“This was an incredibly advanced, coordinated assault that exploited the fact that we stored 560 million customers’ full names, addresses, phone numbers, and credit card details in a cloud database with no multi-factor authentication,” said Richael Mapino, who oversees an organization that charges a $4.50 convenience fee to inform you your data was stolen. “ShinyHunters are a very sophisticated threat actor. You try having a system that requires a password and a second thing.”
“We’re seeing a pattern here,” admitted Undrew Aitty, glancing at a fresh SEC filing that his lawyers were already describing as “largely aspirational.” “But the truth is, when you are responsible for the insurance claims, prescriptions, test results, and surgical records of one in three Americans, you simply cannot be expected to tick every security checkbox. We did require passwords. Long ones, sometimes.”
Separately, a Florida company called National Public Data — which you have never heard of, never consented to give your data to, and which scraped your name, address history, relatives’ names, and Social Security number from public records databases and sold them as a commodity — confirmed that a threat actor had purchased this data for $3.5 million and published it on a dark web forum. The breach covered 272 million Social Security numbers, representing 60% of all SSNs ever issued by the IRS. The company filed for bankruptcy in October 2024 and shut down in December 2024, leaving no one to sue, no one to notify, and no mechanism to un-expose the data.
“It’s unfair to expect companies to keep all that information secure,” said Jark Vuckerberg, while deploying a new AI feature trained on private messages users believed were end-to-end encrypted. “There’s just so much of it. At some point you have to ask: who is really responsible here — the corporation that vacuumed up your most intimate personal data into a centralized honeypot for seventeen years, or the criminal who stole it? Personally I think it should be up to operating system makers to collect even more data, like the age and identity of every person on earth before they can use their apps. This time, it should be safe.”
Researchers also discovered a database of 184 million plaintext email address and password combinations, stored with no encryption and no password protection, accessible to anyone on the open internet. The database included credentials for Apple, Google, Facebook, Microsoft, Amazon, Netflix, PayPal, Roblox, and 220 email addresses ending in .gov. The owner of the database could not be determined. The researcher who found it described it as “a cybercriminal’s dream working list.” Industry analysts described it as “Tuesday.”
Meanwhile, a Know-Your-Customer verification platform called IDMerit left a one-terabyte MongoDB database exposed on the public internet with no password, containing the KYC identity documents — the most sensitive category of personal data, collected specifically to verify you are who you say you are — of over a billion people across 26 countries, including 203 million Americans. The database was discovered by researchers, secured, and never publicly attributed to any breach response, regulatory action, or executive consequence.
When asked whether decentralization — giving individuals and communities control over their own data rather than pooling it into a central honeypot — could reduce the surface area of such attacks, Zam Puckerstein replied: “That’s a great idea. We’re actually testing something like that. We call it ‘Your Privacy Matters to Us,’ which is the tagline on the settings page where you can choose between ‘share everything’ and ‘share almost everything.’ The button for the second option is slightly smaller and in gray.”
At press time, companies were reportedly preparing to send breach notification emails to affected users — approximately 14 months after the breach occurred — informing them that their data “may have been accessed” and offering one free year of identity theft monitoring from a subsidiary of one of the companies that caused the breach, provided users click a link, enter their Social Security number to verify identity, and agree to updated terms of service.
In the hours following a sweeping cyberattack that leaked sensitive data from over 184 million user accounts across major digital platforms, executives in the only industry where this kind of catastrophic security failure routinely occurs confirmed there was no realistic way to prevent such incidents.
“This was an advanced, coordinated assault that exploited a misconfigured S3 bucket with public read permissions and no access logging. These things happen,” said Pundar Sichai, who oversees an organization that once employed thousands of engineers to implement two-factor authentication. “Besides, in five years most people won’t have jobs or reputations anyway — AI will generate better versions of both.”
“We’re seeing a pattern here,” admitted Cim Took, glancing nervously at his second iPad. “But the truth is, no system is ever completely secure. Except maybe the one used for executive bonuses.”
In response to the breach, several firms issued press releases assuring the public that their data “matters deeply” and promised to “continue enhancing our security posture” — a phrase critics noted is now appearing in phishing emails themselves.
“It’s unfair to expect companies to keep all that information secure,” said Natya Sadella, while remotely disabling a whistleblower’s LinkedIn profile. “There’s just so much of it. Honestly, people should feel honored their data was even valuable enough to be stolen.”
When asked whether decentralization could reduce the surface area of such attacks, Zark Muckerberg replied: “That’s a great idea. We’ve actually been testing something like that internally. It’s called a whiteboard.”
At press time, companies were reportedly preparing to launch a new “Privacy Dashboard,” where users can view how their data was leaked in a clear, easy-to-navigate timeline — before quantum computers decrypt it all anyway, thanks to most organizations treating post-quantum encryption like Y2K with better branding.
In the hours following a massive data leak where data from almost all Turkish citizens was exposed, users of the only industry where this kind of mass security failure routinely happens concluded there was no way to prevent such breaches from taking place. “The data breach involved 85 million people, and that happens to be also the population of Türkiye, but sometimes these things happen and there’s nothing anyone can do to stop them”, said Oysel Vek, echoing sentiments expressed by millions of individuals who post their names, religion, sexuality and personal information into centralized computer networks in order to send cat memes to one another. “And besides,” he continued, “we’re mostly just talking about all personal data, including that of relatives, bank details, title deed information, and addresses of every resident in Türkiye. There’s much more to life than these things.”
“It’s a shame, but what can we do?” asks Melon Usk, quizically raising his eyebrow. “It’s not like we have some kind of alternative open source platform that lets each person and organization control their own data. ” When asked about WordPress, which powers 4 in 10 websites in the world, he exclaimed, “Are you kidding? I want videoconferencing, chats, events, payments, profiles, and I want it all in real time with slick notifications. If I am going to check my phone 10 times a day, and share the latest controversy with my friends it’s definitely not going to be on that old software. That’s the modern internet industry. But they better beware, if WhatsApp wants to sell my data, I’ll show them!” At press time, millions of people around the world were seen switching from WhatsApp to Telegram and Signal, in an effort to escape putting all their data, conversations, money and votes in one place.
This article is an homage to The Onion’s article about mass shootings that happen with some regularity in the USA, which is reposted every so often with only the dates and names changed. Here is last year’s article.
In the hours following a massive data leak where data from almost all Brazilians was exposed, users of the only industry where this kind of mass security failure routinely happens concluded there was no way to prevent such breaches from taking place. “This is literally hundreds of millions of people, but sometimes these things happen and there’s nothing anyone can do to stop them”, said Bark Megor, echoing sentiments expressed by millions of individuals who post their names, religion, sexuality and personal information into centralized computer networks in order to send cat memes to one another. “And besides,” he continued, “this only happened because some employee uploaded a spreadsheet with usernames, passwords and access keys into a GitHub repository. Mistakes do happen, after all.”
“It’s a shame, but what can we do?” asks Wenin Denig, quizically raising his eyebrow. “It’s not like we have some kind of alternative open source platform that lets each person and organization control their own data. ” When asked about WordPress, which powers 4 in 10 websites in the world, he exclaimed, “Are you kidding? I want videoconferencing, chats, events, payments, profiles, and I want it all in real time with slick notifications. If I am going to check my phone 10 times a day, and share the latest controversy with my friends it’s definitely not going to be on that old software. That’s the modern internet industry. But they better beware, if WhatsApp wants to sell my data, I’ll show them!” At press time, millions of people around the world were seen switching from WhatsApp to Telegram and Signal, in an effort to escape putting all their data, conversations, money and votes in one place.
This article is an homage to The Onion’s article about mass shootings that happen with some regularity in the USA, which is reposted every so often with only the dates and names changed.
The social platforms we use today are all centralized under the control of large corporations. Our conversations, our identities, private documents, and public announcements are hosted on their servers. The vast majority of people online live in a feudal society dominated by Facebook, Amazon, Google, Apple and Microsoft. This is also true of small businesses, whether they sell their products on Amazon, release apps on Apple’s store, announce events on Facebook, reach their followers on Twitter, or blog on Medium. They even put their brand behind the brand name of the rent-seeking platform that hosts the infrastructure.
But the societal problem is even bigger. As a society, the problem is that our public forums, spaces and discourse take place on privately owned platforms. The mentality of “I built it, so I own it” has led to Mark Zuckerberg controlling Facebook, Jeff Bezos controlling Amazon, and so on. With great power comes great responsibility, and these companies are often held directly responsible to somehow do “the right thing” on an impossibly wide variety of circumstances. Even public interest groups like EFF admit it may be infeasible. Zuckerberg was excoriated by Congress in 2019 for not taking down certain content, but then in 2020 grilled for censoring similar content. For everyday communication online, most people are forced to trust large corporations whose interests may not align with our own. The issues of deplatforming and money in politics are actually secondary symptoms of this main problem.
The Solution
The solution is open source software that can move our digital society from feudalism into a free market. Such software is motivated by principles of agorism and distributism rather than pure capitalism. Tim Berners-Lee invented the Web, Linus Torvalds built Linux, and Vitalik Buterin launched Ethereum, but they don’t “own” it. The Web, Linux and Ethereum are permissionless for anyone to use, and this is precisely why they have led to an explosion of wealth for the world.
There was a time when America Online, CompuServe, Prodigy and MSN were the companies through which most communication online happened. People dialed in and chatted. But the open Web changed all that: companies were suddenly able to serve their websites with a large free market of hosting providers, and domain names were available to everyone. People no longer needed to rely on infrastructure provided by AOL, cable channels, TV stations, radio stations and other gatekeepers. As a result, the Web has led to trillions of dollars in business models like E-Commerce and Software-As-A-Service, which would not have been possible otherwise. Google and Amazon could not have built their businesses on top of AOL; they were given their start precisely because the Web was open.
Today, WordPress powers nearly 40% of all websites in the world. But it is good for one-way publishing (Web 1.0) . When it comes to community software (Web 2.0), people turn to Facebook, Twitter, WhatsApp, YouTube to connect and interact. In order to liberate people from this feudalism, there has to be an open source solution like WordPress, but to provide an alternative to those companies. Just as the Web once provided an an alternative to AOL, MSN, etc.
The Qbix Platform allows you to deploy your own open source Community Server, and totally own your data, brand and relationships. No more need to pay Facebook to reach your own audience. No need to worry if Apple kicks your app off their Store. You’ll always be accessible on the open Web. And if hosting on Amazon gets too expensive, back up your database and move it somewhere else. Install third party plug-ins from a growing ecosystem of developers, built on open standards. The software is yours. Do with it as you wish.
Learn more about it in the video below. If you to get in touch, back our project, or just want us to build an app for your community, fill out the form at Qbix.com
Okay, that was quick. A few months after writing that we hit 7 million users, we blew past our 8 millionth user. By now, over 8 million people across more than 95 countries have installed Groups and Calendars.
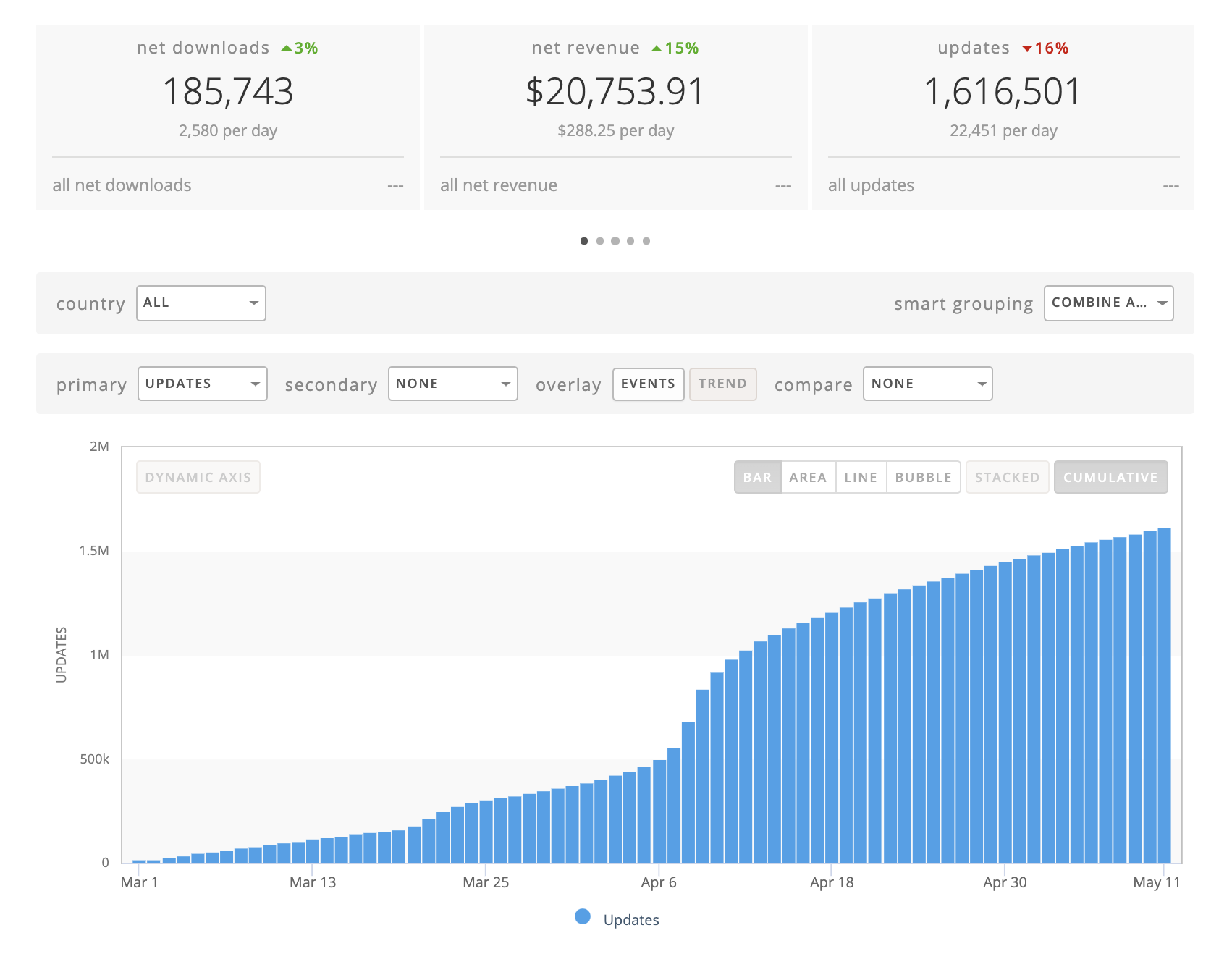
But, how many people have kept our apps after downloading them? We learn that information whenever we release a new version of our app. Over the next 30-90 days, we are able to see how many people are updating the apps. We began to do a “phased release” and closely monitor if any of our users experience crashes or other problems. After our latest release this March, how we found out that at least 1.5 million people have updated the Groups app:
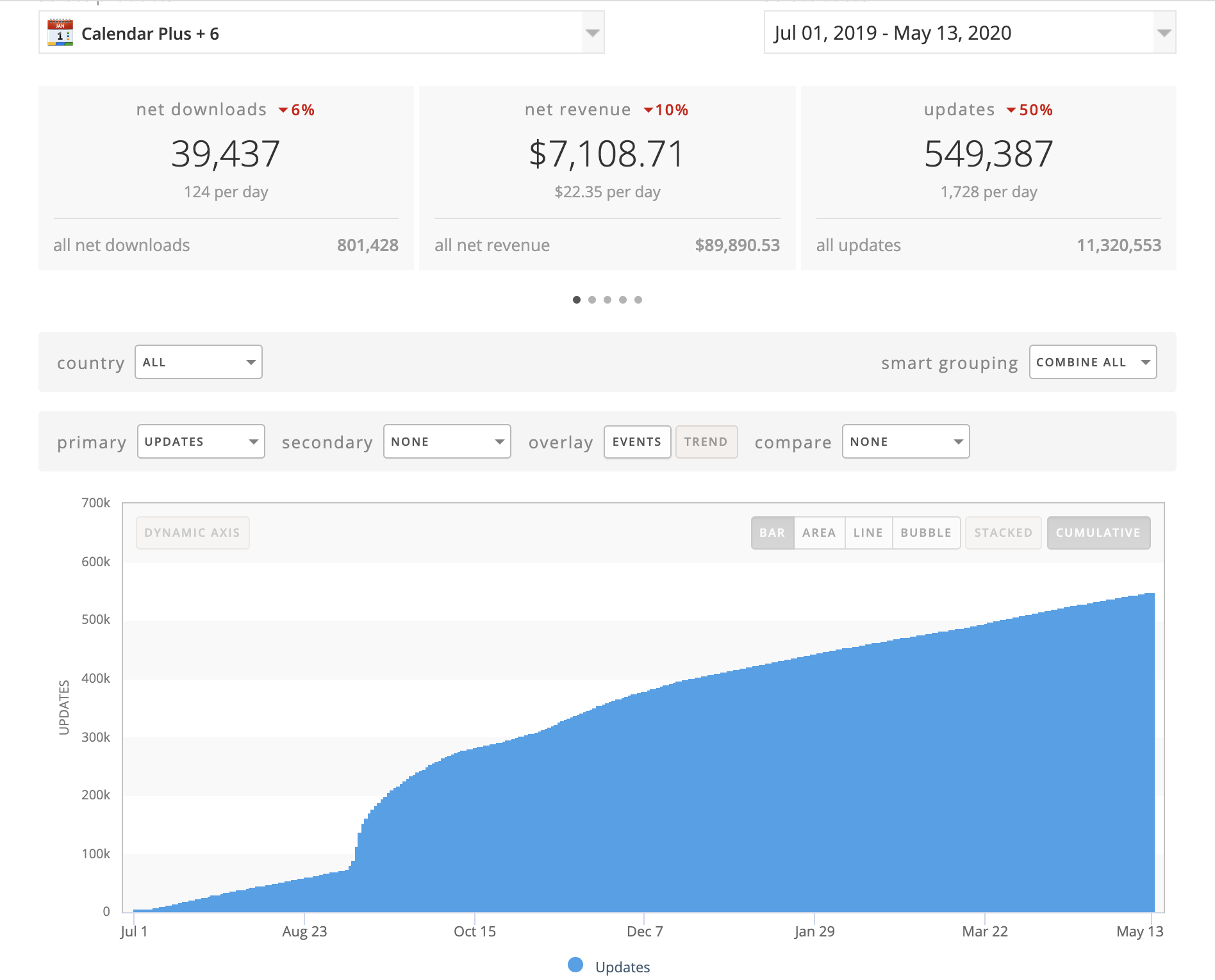
Last August, we found out that at least half people have updated the Calendars app:
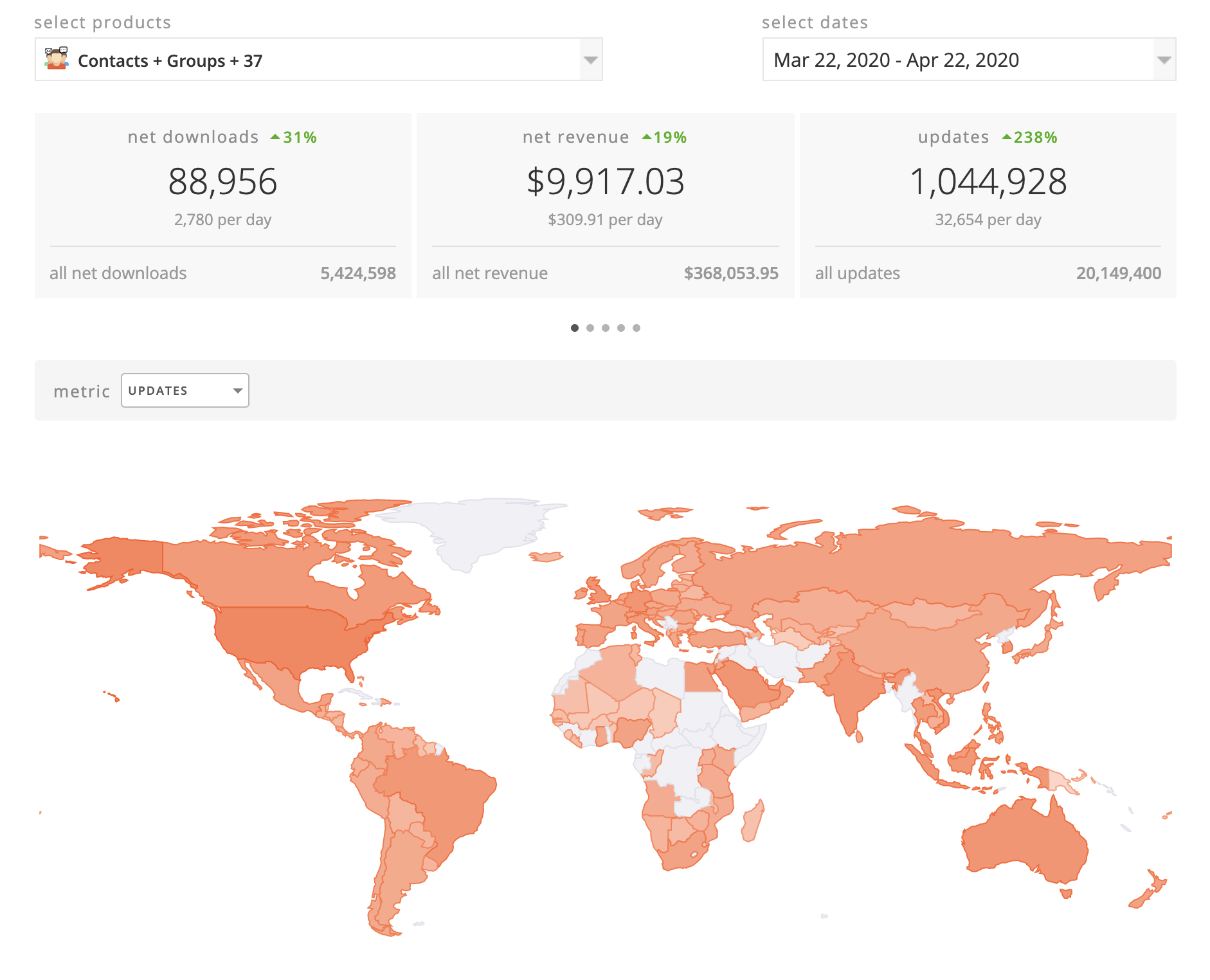
Here is an overview of the countries these Groups users are in, from the period of March 22 – April 22. Around half of them are in the United States:
We passed a new milestone recently: Qbix apps have attracted 7 million users from around the world. Here are some more cool stats:
Qbix apps are used over 1.2 million times a month
by people in nearly 100 different countries.
They are translated into 15 languages by hand,
and another 100 languages using Google Translate
Every day, 2000 new users discover our apps,
including 300 community leaders and 80 business owners.
We have 80,000 community leaders to date.
The Calendars app runs continuously on 27,000 computers
Below, we put together an interactive visualization of all our users around the world, complete with sample reviews in their native languages. Feel free to rotate the globe below, tap on some countries and explore the reviews in the app store. Those white animated pings you see represent people actively using our apps around the world!
Of course, we are pretty proud of reaching this milestone. But our biggest announcements are still ahead this year. They have to do with the Qbix Platform and the QBUX Token.
Now that 2020 is here, let’s look at what we can expect from the next decade in software. As Web developers, our solutions can help shape the organizations we work for. The tools we build and the architectural decisions we make have a compounding effect on society at large. What are the new trends, and will they help empower or enslave people?
The Old Trends
The trends in the last 10-20 years have led to more and more centralization of the Web, consolidation of power in the hands of the largest services (Facebook, Google, Amazon, Reddit) and their extended ecosystems. Between these and the large publications, the “independent Web” has suffered a tremendous setback. Most people and organizations trust large corporations with proprietary algorithms to manage their data, identity and brand. This has led to massive new issues for individuals and society, involving governments and corporations, and how we all relate to one another. Attempts to resolve these issues have spawned some projects to decentralize the Web.
When the Web was born, browsers rendered HTML documents, and there was very little support for client-side programming. Whatever Javascript support was introduced over the next decade was inconsistent because of the browser wars, and led to Javascript libraries to bridge the gap, of which jQuery emerged as the winner. The last 10 years saw the rise of Angular and React, new versions of Javascript and HTML5 Web APIs, which finally made front-end Web programming a powerful proposition on the most widely deployed platform in the world.
Client-First Web Apps
As Javascript was maturing, a conventional wisdom has developed among most Web developers, that you should render the HTML on the client side, and then progressively enhance it with Javascript. This was considered best practice and recommended by pretty much every authority from 2009 to 2018.
In this decade, Web developers will turn this conventional wisdom on its head, and start to consider progressive enhancement to go the other way:
First, develop static HTML, CSS and Javascript
Make Javascript fetch data from servers, render it on the client
Progressively enhance the site for older environments (Server-rendered HTML)
What follows are multiple reasons for why this is the better approach going forward. This one shift in how we approach Web development will have profound technological and societal implications.
Distributing Software
1. Separation of concerns. It pays to decouple the rendering of an interface from the delivery of code / markup. That way we are not tied to one type of app delivery — that of a server on the web sending our executable code. We are able to sideload apps, download them from app stores, and update specific files when they have changed. And we use one language for each task, too: JS is the code. HTML / Handlebars / etc. can be used for templates / markup. CSS is used for presentation. JSON or XML is used for data. After you have done this, if you want to pre-render HTML on a server for AJAX, you can, but will start to feel “dirty” as you’ll be coupling things unnecessarily again. Things are going this way as headless CMSes are making an appearance, while Cordova, Ionic and React Native represent other ways of delivering code through app stores.
2. Trust. You can’t trust what code is running remotely (although Signal has been experimenting with using Software Guard Extensions by CPU makers, originally designed for DRM, to go the other way and ensure what code runs on a server). But even if you can, you have no guarantee some other process won’t steal or corrupt your data. The Trusted Computing Base should not include arbitrary amounts of remote sites shipping code at any time. Decoupling how the code is loaded (see point #1) onto your client allows you or your user agent to verify checksums and certify that it is indeed the code you think it is. And it is that code that should be managing your data and using the personal keys on your device. Package managers and app stores will be able to distribute code that has been audited by third-party security firms, and people will be able to trust them.
3. Decentralization of Code. As the next decade unfolds, we will find that code bases don’t necessarily have to live shrink-wrapped on a specific server. Rather, clients can use multiple interoperable software modules and versions and can have multiple app stores and distributors in the future helping maintain repos and package managers for end-users and organizations. We will probably see automated package management become more user friendly in the 2020s, as we already have a docker container culture, we have browser based package managers etc.
Data Ownership
4. Decentralization of Data. This is the big one in terms of effect on society. By having web servers render your webpage, you are implicitly locking yourself and your organization into the type of model where the servers store and access the data in a private database. They have enough data to render everything, apply access control rules to manage what you can read and write, and so on. Instead, we as a society need to empower people and their client side apps, and push the logic of fetching data, caching it and assembling it to the user agents. We can use capabilities / access tokens for data instead of a centralized site rendering HTML. In this way, always inverting the progressive enhancement is an activist position to change society against the abuses of power like the ones listed here.
5. Reliability After the 2015 ISIS attacks in Paris, countries around the world expressed solidarity with the French people. French colors were flown, but similar-sized attacks at the same time by ISIS in Beirut were totally forgotten. Facebook rolled out a feature to customize one’s profile with the French flag superimposed, but only the French flag. So we used the Qbix Platform to quickly build a small app called customizemypic.com to allow anyone to change their profile picture to a flag of their choice. The goal was to make a statement and express solidarity with people in Beirut, Baghdad and other areas hard hit by terrorism. Today, that same app is no longer able to do its core function because Facebook removed any way for users to give permissions to apps to upload a photo on their behalf. This is what happens when you rely on third parties to announce what you can and cannot do with your own profile picture. The most extreme reliability is achieved by an offline-first approach, which is a close cousin of the client-first trend that will grow in the 2020s.
6. End to End Encryption. Server-side rendering perpetuates a culture where the server has all the data unencrypted. Even if the data is encrypted at rest, the served holds all the decryption keys and is one central target for hackers, government agencies, and advertisers. Rendering things client-side goes hand-in-hand with a culture of people storing their own keys on devices of their choice, and letting key management and password management be the domain of operating systems and trusted computing bases, not random websites.
Data Delivery
7. Bandwidth. Ever since Steve Jobs presented WebObjects, we have wanted sites to render dynamically. Well, that often involves looping through various items and rendering each one. It is extremely wasteful to send the HTML results of rendering hundreds of items to a client, when you could have just sent the data, which would then be “hydrated” into 5. templates by the client. However, I can understand pre-rendering just the items above the fold (if one could estimate this number, not knowing the size of the window on the first request).
8. Caching Issues. Often, you have subtle and pervasive changes on every page when a person is logged in vs out. (I should remark that “logging in” into a site itself is an artifact of “centralized” thinking, but I digress.) Their avatar might be rendered in various places. New links are shown that might not be available otherwise. And new information may be shown that access control and discovery suggestions determines they can see. If you render everything on the served, there is no way to cache most of the fragments of the page, because they are changing. If you render client-side, all this comes for free.
Next Steps for Web Developers
So by now you may be convinced that “client-first” is a good design pattern and progressive enhancement can be implemented later, by “speeding up” the first render, and by making it available to “dumb” crawlers and user agents who don’t execute Javascript in 2020. Here is how that would actually look, in actionable terms:
9. Preloading. Okay, now that you are rendering everything client-side, you can implement a mechanism to preload data from the server. Perhaps put all the JSON in one file and send it over on the first render. Which — remember — happens only when you use a Web Browser to visit a page directly, a very specific scenario. Every other request besides that, including subsequent requests from a web browser, don’t need this preload. It’s an extra flair you can add for that specific use case. So the preloaded data comes and your Javascript will already have it and will render the HTML synchronously and quickly.
10. Static Site Generation. The most popular static site generators today are still pretty narrow in their use-case. They help with blogs and publishing, eg Jekyll, Hugo, etc. But if you already have a dynamic site, you can sort of transform it into a static site by having a server-side script request some (dynamically specified) set of pages and render them to some related static html documents, and then begin sending 301 redirects on the dynamic pages to permanently tell browsers to go to the static pages in the future. (Because rewriting all links in your site may be infeasible). This approach runs into problems I described in point 5 — so a naive approach would only work for publicly accessible pages that don’t change when someone is logged in. You may still need to add client side JS to “fix up” at least the basic affordances for logged-in users.
11. Caching, Throttling, Batching. Every function that issues a GET to a server could be made smarter to take into account caching, throttling, and batching of request. In Qbix Platform we have middleware methods like Q.getter and Q.batcher which take any getter functions and transform them into ones that do the above things. They work with instances of the Q.Cache class which have adapters to cache in the current document, in sessionStorage or localStorage. (And later maybe in IndexedDB etc.) They have hooks for additional steps when serializing and unserializing objects etc.
12. Deployment. We have built various scripts in the Qbix Platform to help not just Qbix apps but general websites be deployed, including:
combine.php (which fixes css files to have absolute URLs, minifies, combines etc. all scripts and stylesheets you tell it, and Qbix Platform rewrites links when you add scripts and stylesheets)
urls.php (which goes over all the static files inside the publicly accessible web directory, checks their modification time and builds indexes in php and JSON as to what changed since the last time it was run… allowing clients to eg download a diff of what files changed since last release. If also calculates hashes for SRIs and Qbix apps automatically append the correct SRI information when rendering certain tags, and the correct timestamp for cache-busting.)
static.php goes over your site, whatever it is, and generates a static version that you can serve, and 301 Redirects for the rest. It helps turn a lot of your public pages into a static site.
bundle.php (which builds a bundle for Cordova app deployment. The client-side Cordova plugin from Qbix intercepts requests and sees if there is already a local version in the bundle, and serves that if needed. This works with https as well. One of the many client-side Cordova features that allows us to turn websites into native social apps. Sadly, Apple doesn’t support Service Workers or AppCache for WebView.)
These PHP scripts are part of a larger open-source ecosystem that we developed to help Web Developers take advantage of modern security practices and build advanced social web / native apps like this one for Andrew Yang.
The Platform is free and open source, with tutorials and a guide on how to use it. If you are interested in learning more about the Qbix Platform, then reach out to us. And if you have a meetup or group that you’d like us to present and answer questions, let us know.
On the 30th anniversary of the launch of the Web, we remember how it disrupted the centralized social networks of the day: America Online, MSN and Compuserve. However, Web 2.0 has made social media dominate our daily lives, and our data, identity and relationships are now stored “the cloud” hosted by one or another huge corporation. With great power comes great responsibility, and it’s time for Web 2.0 to be decentralized.
Gatekeepers. Could Google, Amazon and Facebook have emerged on top of AOL/MSN/Compuserve? They were built on top of the Web, originally accessible through Web Browsers, because the Web was permissionless and completely took over.
Rentseeking. Brands are not always happy to have to pay the platforms.
Encryption #1. The other day Zuckerberg said he wants to build privacy and encryption into Facebook, but people don’t buy it.. When the large companies say WhatsApp or Telegram is secure on the back end, we just have to trust them. The only way to be sure is to install open source products on our own servers and devices, with client software that uses end-to-end encryption.
Encryption #2. Just this week we heard that Russia’s passing laws that can land you in jail for criticizing the government (it was already doing this), and thousands turned out to protest Russia’s bill curtailing internet freedom. Given how many people live in Russia, China, a question arises whether free speech is important at least for small, local networks.
Monopolies. Again just this past week, Elizabeth Warren has support on the left and right when it comes to calling for breaking up these monolithic networks which got there via network effects.
Government action is a heavy hammer that can be wielded as a last resort. The industry has been repeatedly disrupted in the past, where open source projects disrupted closed, centralized networks:
The Web disrupted America Online, MSN and Compuserve
Wikipedia disrupted Britannica and Encarta
Craigslist disrupted classifieds in Newspapers
Blogs powered by WordPress comprise 30% of websites in the world
There needs to be an open source software platform that any community anywhere in the world can run on local intranets, whether it’s a university in Bulgaria or a village in Africa. Collaborating on a document shouldn’t need the signal to go to google docs servers. Making plans with friends, or booking a reservation locally shouldn’t need Facebook.
PS: This video is the first in a two-part series that puts our work in a larger societal context. It was taken with our new blackboard setup, but a bit before we improved the lighting. There’s something about appearing in front of a black background (no shadows) and suddenly being able to draw on it, that seemed like a good format for educational videos.
This post is about truly decentralizing the Web. We will write another post about making the Web more social, especially on mobile devices. To achieve both of these objectives, Qbix is working on a new Social Web Browser.
We are coming up on the 30th anniversary of the invention of the Web. It has been one of the biggest drivers of economic and technological innovation on the Internet. It has lowered the barrier to publishing and accessing information for people around the world. It has enabled commerce and online payments to go mainstream. And it has done all this in a radically open-source way: the HTML source code for every web page can be easily accessed via the browser. As a result, the Web has led to an explosion of wealth and innovation, removing the old gatekeepers.
However, the Web’s client-server design has also led to new gatekeepers and centralization. People have come to rely on giant, monolithic websites to connect them, and trust them with their data, identity and brand. Sometimes that results in epic security breaches by hackers, bulk collection of data by spy agencies, betrayals of trust, revocation of access, With Google, Facebook, Apple, Microsoft and Amazon, the Web has become, in many ways a Feudal society. With a few Root Certificate Authorities, we also centralize our trust in a few companies. Finally, the Domain Name System uses a centralized, although federated, database, so domains have to be bought through a registrar, and maintained.
But what if we challenge some of these assumptions? For example, what if a regular user didn’t need to buy a human-readable domain name, maintain it, and pay for a hosting company to host on that domain? What if identities and domains were as cheap to create and maintain as files?
Until around 2010, it was even harder. To have a website, most users would have to have their own server in a data center, or rely some limited shared hosting service. Most people opted to use let companies like Facebook host their whole identity online instead. Amazon figured out that letting people share managed virtual machine instances was good savings. Today, that’s called “the cloud”, but it’s still under the control of some landlord – Amazon, Google, DigitalOcean, etc.
It’s 2018, and still the easiest thing we have today is using some web based control panel running on some shared host that charges $5/month or something.
Here is what we should have instead:
End to end encryption
One giant, actually decentralized cloud composed of all nodes running the software
Storing chunks of encrypted data using Kademlia Distributed Hash Table, a technology that’s available since 2002 and used in BitTorrent and MaidSAFE
All underlying URLs would be non-human-readable and clients would display (possibly outdated) metadata like an icon and title (this metadata may change on the Web anyway). Storing and sharing could occur using QR codes, NFC bluetooth, Javascript variables, or anything else. For static files, the links could be content-addressable.
Communities would likewise be just regular users, rather than private enterprises running on privileged servers running some software like github is now. No more server side SaaS selling your data or epic hacks and breaches.
Users would have private/public key pairs to auth with each community or friend. They would verify those relationships on side channels for extra security if needed (eg meet in person or deliver a code over SMS or phone). Identity and friend discovery across domains would be totally up to the user.
Push notifications would be done by shifting nodes at the edges, rather than by a centralized service like Apple or Google. In exchange for convenience, they can expose a user to surveillance and timing attacks.
Validation of transactions can be done by random participants in the network, such as the 40,000 people around the world running our Calendar App, but unlike Proof of Work Mining in a way that puts next to no strain on their computers.
No more waiting endlessly to be “online” in order to work in a SaaS document. The default for most apps is to work offline and sync with others later.
Instead of central authorities, everything is peer to peer, with a data stored encrypted in a truly decentralized cloud. The only “downside” is the inability to type in a URL. Instead, you can use one or more indexes (read: search engines) some of which will let you type existing URLs, or something far more user friendly than that, to get to resources.
Domains and encryption key generation would be so cheap that anyone can have a domain for a community of any kind, or even just for collaborating on a document. There won’t any longer be a need for coupling domains to specific hardware somewhere, and third party private ownership/stewardship of user-submitted content would be far less of a foregone conclusion, fixing the power imbalance we have with the feudal lords on the Internet today.
Once built, this can easily support any applications from cryptocurrency to any group activities, media, resources etc.
If you are intrigued by this architecture, and want to learn more or possibly get involved, email us.
 Get blog updates
Get blog updates